Traffic Refinery
Cost-aware network traffic analysis.
Relationships between systems costs and model performance would ideally inform machine learning pipelines during design; yet, most existing network traffic representation decisions are made a priori, without concern for future use by models. To enable this exploration, we have created Traffic Refinery, a system designed to offer flexibly extensible network data representations, the ability to assess the systems-related costs of these representations, and the effects of different representations on model performance.
System Overview
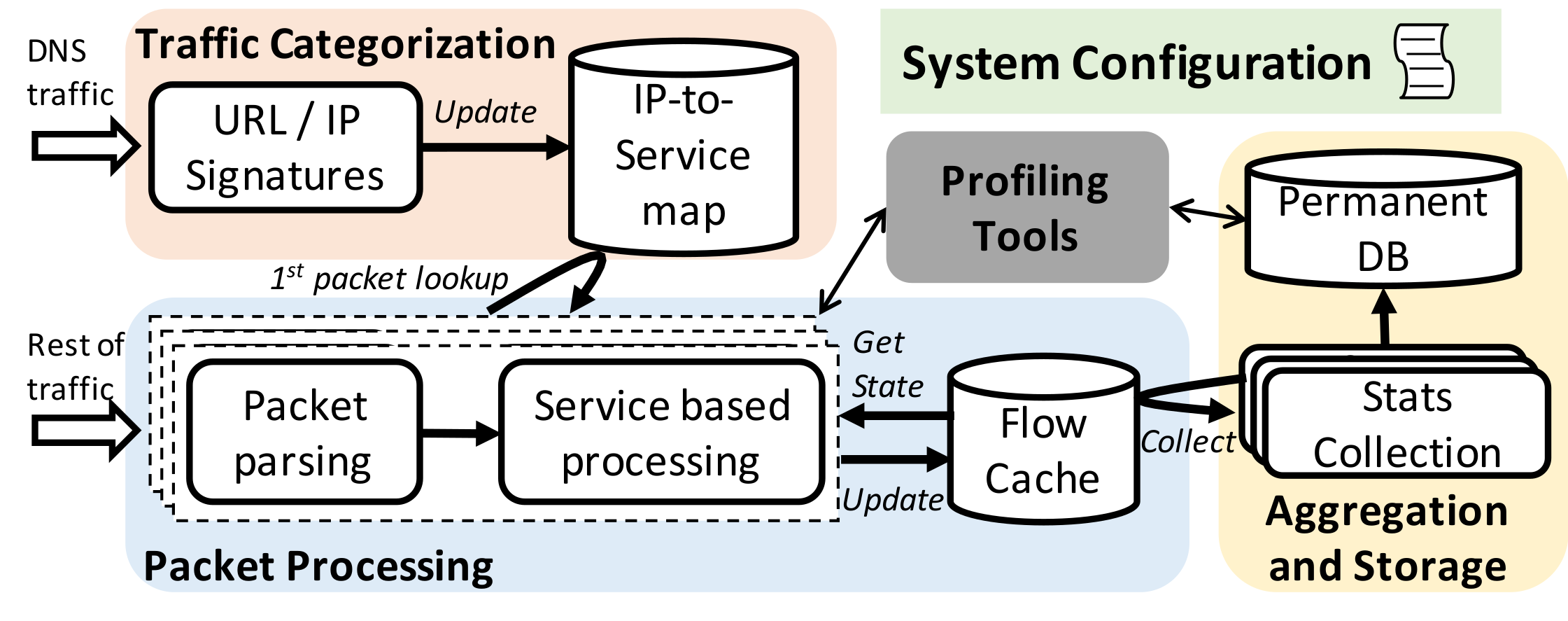
The figure shows an overview of the system architecture. Traffic Refinery is implemented in Go to exploit performance and flexibility, as well as its built-in benchmarking tools. The system has three components:
- A traffic categorization module responsible for associating network traffic with applications
- A packet capture and processing module that collects network flow statistics and tracks their state; moreover, this block implements a cache used to store flow state information
- An aggregation and storage module that queries the flow cache to obtain features and statistics about each traffic flow and stores higher-level features concerning the applications of interest for later processing
tl;dr: What Can You Do with Traffic Refinery?
- Traffic (i.e., flows) are classified as “services” using either DNS domains or IP prefixes that the user can provide. Note: DNS is increasingly encrypted, making this method less reliable. An area of ongoing research is privacy-preserving flow categorization.
- For each service, users can select from a set of existing features or create additional ones to collect along with their frequency.
- The system-related costs of each feature can be profiled, enabling users to explore tradeoffs between ML model performance and feature costs in their particular environment.
Why is Traffic Refinery Necessary?
Network management increasingly relies on machine learning to make predictions about performance and security from network traffic. Often, the representation of the traffic is as important as the choice of the model. The features that the model relies on, and the representation of those features, ultimately determine model accuracy, as well as where and whether the model can be deployed in practice. Thus, the design and evaluation of these models ultimately requires understanding not only model accuracy but also the systems costs associated with deploying the model in an operational network.
To highlight the need for Traffic Refinery, we show results from our prior work by training multiple ML models to infer the resolution of encrypted video streaming applications over time using different data representations: 1) using only L3 features, as would be available using netflow; 2) adding transport layer features; and 3) adding application layer features to L3; and combining all features. The figure below shows the precision and recall achieved by each representation.
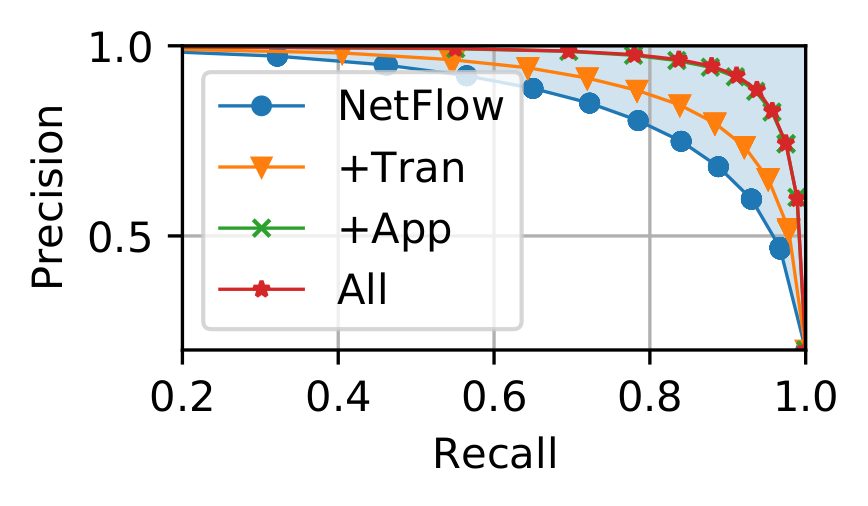
As one might expect, a model trained solely with L3 features achieves the poorest performance. Hence, relying solely on features offered by existing network infrastructure would produce the worst performing models. On the other hand, combining Network and Application features results in more than a 10% increase in both precision and recall. This example showcases how limiting available data representations to the ones typically available from existing systems (e.g., NetFlow) can inhibit potential gains, highlighted by the blue-shaded area.
Of course, any representation is possible if packet traces are the starting point, but raw packet capture can be prohibitive in operational networks, especially at high speeds. The figure below shows the amount of storage required to collect a one-hour packet capture from a live 10 Gbps link.
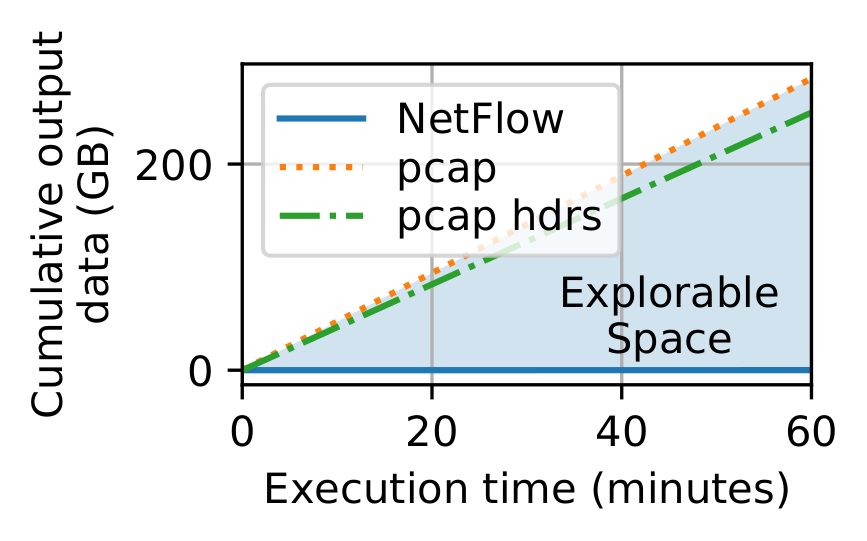
Traffic Refinery provides a new framework and system that enables a joint evaluation of both the conventional notions of machine learning performance (e.g., model accuracy) and the systems-level costs of different representations of network traffic.
Publication
The research paper behind Traffic Refinery was accepted to SIGMETRICS 2022, and published in ACM POMACS in December 2021.
Citation bibtex
@article{10.1145/3491052,
author = {Bronzino, Francesco and Schmitt, Paul and Ayoubi, Sara and Kim, Hyojoon and Teixeira, Renata and Feamster, Nick},
title = {Traffic Refinery: Cost-Aware Data Representation for Machine Learning on Network Traffic},
year = {2021},
issue_date = {December 2021},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {5},
number = {3},
url = {https://doi.org/10.1145/3491052},
doi = {10.1145/3491052},
journal = {Proc. ACM Meas. Anal. Comput. Syst.},
month = {dec},
articleno = {40},
numpages = {24}
}